 Back to Technical Articles
Back to Technical Articles
Technical Article: Renderer and shader architecture
 |
Highly optimized 3d pipeline |
|
Re-entrant modular shader systemTM |
|
Lighting and shadowing |
|
LOD and curved surfaces |
Highly optimized 3d pipeline
The Shark
3D engine uses most modern engine technologies including patch-based
rendering, hardware T&L and efficient world management to provide the
maximum performance.
For today's 3d cards and drivers, rendering high polygonal objects only costs few 3d driver calls. The rendering architecture and 3d object data formats of Shark 3D are optimized for optimal performance and for high polygon counts, taking optimal advantage of the 3d hardware of today's and tomorrow's 3d cards. This of course includes full hardware T&L and multi-texturing. It also includes bandwith optimizations by using for example static vertex buffers and display lists as much as possible.
In practice this means that in most situations, not the engine is the bottleneck but the 3d driver (e.g. OpenGL) and the 3d hardware. This in general improves the performance, since today's 3d hardware is quite powerful, and 3d drivers usually are optimized very well. Furthermore, the engine can take optimal advantage of better drivers and better hardware for free.
Re-entrant modular shader systemTM
Overview
A standard realtime shader system today provides a shader language to allow a configuration of the renderer, for example to define rendering passes and texturing modes.
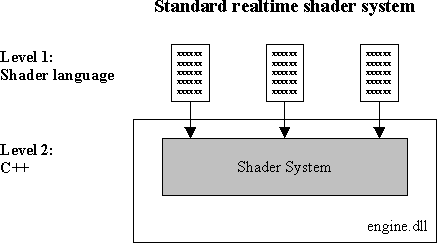
The disadvantage of this approach is the following. New advanced rendering features cannot be implemented in a limited high-level rendering language. C++ is necessary. When having only the standard shader system, this means that a new C++ rendering feature requires changes of the rendering code of the engine.
This means: no real modularity, even if the renderer is built out of components. For every project, you get different variants of your engine code, because you have to adjust your engine. BTW, this problem is not limited to the rendererer. This is a problem everywhere in the engine if your engine is not really modular.
In contrast, the Shark 3D engine provides a re-entrant modular shader systemTM. This means that all rendering functionalities are completely moved into independent, decoupled shader components.
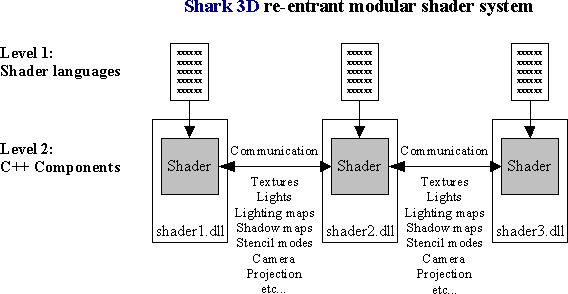
All advanced rendering effects included into the engine SDK are implemented in separate, independent shader modules.
For example, in Shark 3D, the core engine renderer does not know anything about mirroring. Especially, mirrors are not hardcoded in the renderer. Instead, a mirror is implemented by an independent shader module. Any additional advanced specialized mirror effects for example using rendering into a texture, texture coordinate distorsion, vertex programs and pixel programs are be implemented in independent shader modules. No change at the renderer itself is necessary.
In the same way, additional low-level rendering features can be implemented by simply adding a new shader module. No line of existing C++ code has to be changed.
Power of non-realtime shader technology in realtime
The Shark 3D re-entrant modular shader systemTM brings the power of advanced modular shader systems of non-realtime renderers into realtime 3d graphics.There are interesting analogies between realtime and non-realtime rendering architectures. For example, if non-realtime renderers like 3ds maxTM would have the same limited rendering architecture as a standard realtime shader system, this would mean that for every new rendering effect (for example a specialized hair shader) the core rendering code of 3ds maxTM would have to be changed. Instead of writing plugins, each developer would have to create a modified variant of 3ds maxTM. Of course, this is not only very inflexible, it is also not possible in practice. But a universal modular shader system as used for example by 3ds maxTM provides real flexibility and is the foundation for realistic rendering.
Shark 3D brings the power of a really modular shader system into realtime 3d graphics. There is no renderer with fixed functionality, which only can be enhanced or customized by modifying C++ code. Instead, the renderer is completely modular down to low-level rendering effects. This is unique, and opens unique possibilities for high-end game projects.
Creating shaders by configuration
New shaders can be created by configurating shader components without needing C++ or script code.This includes using mulitple rendering passes, multi-texturing, texture coordinate generation and modification, shader animations, and much more. Using all these features don't require scripts or C++-code.
Another feature of configuration is to define different rendering techniques depending on the available hardware. Depending on the presence of particular 3d-card features, one of several shader variants is selected.
Also new shader components can be included into the game engine simply by configuration.
Shader modifier trees
A 3d object needn't have only one single shader assigned to it. Instead, multiple shader components may be combined to shader modifier chains or a shader modifier trees. Such a chain or tree may be assigned to a 3d object.Building shader modifier stacks and trees can be done purely by configuration. Thus, combining features of different shaders to generate a particular new unique shader can be done purely by configuration. No line of C++ code has to be changed.
For example, a mirror is not simply implemented by a single shader. Instead, at least two shaders work together. These two shader build a shader modifier chain, which is assigned to the mirror object. The first shader component implements the mirroring functionality. This shader may for example generate a texture containing the mirror image. The second shader component is used to render this texture, and possibly to apply additional effects, for example distorsion. By this, the mirroring feature can be combined with other features provided by different shaders.
A second sample is building a light source shader chain. A light modifier shader may be added on a light shader to add additional functionality. For example, the basic light shader itself does not know about glow. Instead, glow is implemented as light modifier shader to this basic light shader.
Another example are texture coordinate modifiers. A shader can be configured to use additional mapping coordinate modifiers. Thus, algorithms for calculating a texture transformation matrix or for generating texture coordinates can be implemented independently from the shader itself.
Programming the 3d chips
Parallel to the publications of the first 3d cards supporting a user-programmable 3d pipeline, the Shark 3D engine already has had full support of shader programs. This includes "vertex shaders" and "pixel shaders" using Direct3D, and vertex programs, texture shaders and color combiners using OpenGL extensions.What we wanted to avoid from the beginning is to implement new features into the engine in a special way. It is obvious that also in the future new cards with new features will come out. Because of this, we came to the conclusion that the right way is to implement a general engine architecture being open for new rendering features.
The challange now was to implement a powerful high-level framework, for example, providing full access to pixel and vertex shaders without having the need to use C++, but also not limited to special effects like bump-mapping, but offering access to really all features of today's and tomorrow's cards. This is not easy, since a shader is not only a simple object attached to a 3d object, but has many interactions with other modules for example regarding animations.
For that purpose, we designed a universal shader program smoothly integrated into the engine shader and animation system. The developer can combine the advantages of the configurable shader system, lighting and shadowing engine with vertex and pixel programs of 3d chips, opening for you the gate to new rendering effects.
This is unique - today there are already several engines taking advantage of the GeForce3 features, too, but all of them only got their effects for the price of specialized one-way C++ implementations in their engine.
Shader animation
Any number of independent animation slots can be passed to the shaders, shader programs, including to pixel and vertex shader programs. The shader animation technique is integrated completely into the Shark 3D networking technology.These features are all accessible on a simple configuration level. For example, a sensor volume may start and stop a pixel program shader animation. The animation is controlled by the server, but is executed on the client. Such features can be implemented completely on a configuration level needing only few configuration entries. There is no need for any C++ code or scripting code.
Each animation slot can be configurated in different ways. First, it can be a simple animation, which is played automatically locally on the client, for example for decorative shader animations. But it is also possible to control an animation slot by the server, taking advantage of all advanced animation techniques of the engine, including server-client optimizations and interpolations.
As a very simple example, you can write a shader blending two textures into each other controlled by a script on server-side. You may also provide two versions, one single-pass version using the combine unit of a GeForce 3d card if available, and a two-pass algorithm as fall-back. All this can be done by configuration without any line of C++ or script code.
As another more realistic example, you may write a customized shader for an energy-protected door in a game using animated pixel and vertex programs. This shader may use one automatic animation slot for a decorative energy fluctuation animation, and a second animation slot for fading between an open and closed state of the gate, which is controlled by the server. Also this sample can be implemented without any line of C++ or script code.
Bump mapping
Standard shader components provide dot product bumpmapping (dot3 bumpmapping), including per-pixel diffuse and specular lighting and including a per-pixel specularity definition.This makes it possible to create highly realistic materials usually only known from non-realtime renderings. This includes for example realistic looking cloth, skin, wood, metal, plastic, shells, and much more.
Fullscene shadow volumes
Shark 3D includes standard shader components for fullscene shadowing based on shadow volumes.The fullscene shadowing components can be used both for point lights and projected lights. All objects in the world can cast shadows on all objects, including self-shadowing. Furthermore, all objects in the world including characters and the light sources can be dynamic. The 3d scenes look more realistic and get more depth.
In contrast to simple shadowing techniques, lighting and shadowing looks consistent. For example, if the shadow of a character falls on a pillar, the character shadow disappears behind the pillar in the pillar shadow. By this, the shadows look real without wrong-looking inconsistencies.
Optimized culling and advanced object enumeration techniques algorithms can quickly eleminate many irrelevant occluder objects.
Due to the modular structure of the Shark 3D shader system, fullscene shadowing can be combined with other rendering features in a very flexible way. For example, some standard shaders of Shark 3D combine fullscene shadowing with dot product bump mapping.
Projected lights
Projected textures can be used for example to add projected spot lights.Reduction LOD
The mesh preparation tool can import or precalculate LOD stages of a mesh.When using manual LOD stages, the designer has full control of LOD and can create optimal visual results at minimal polygon counts.
For precalculated LOD stages, additional information is stored so that the runtime engine can interpolate in realtime between two neighboring LOD stages to avoid "jumping effects". The LOD precalculation basically can be applied to any mesh, but depending on the particular mesh this can give good or bad results.
If a LOD stage is drawn directly, no additional calculations are necessary at runtime. The patches of the mesh can be drawn directly. This only needs few calls to the 3d driver.
The advantage of reduction LOD is that any kind of surface details can be modeled. This includes not only curved surfaces, but also fractal surface structures.
RMS (realtime mesh smoothing)
The engine offers realtime mesh smoothing as compact representation of smooth curved surfaces. The smoothing technique of the Shark 3D engine is similar to the subdivision surfaces of 3ds maxTM or the Metanurbs of LightwaveTM, but optimized for realtime.From the point of view of subdivision surfaces, the smoothing technique is a generalization of realtime Loop surfaces. Loop surfaces itself are a generalization of quadratic surfaces. For regular meshes, Loop surfaces are basically equivalent to quadratic splines, both are connections of quadratic surface parts. One difference is that Loop surfaces use a different representation of these quadratic patches. In contrast to splines, Loop surfaces have the advantage of easy support for curved surfaces of non-planar topologies. Objects needn't be built of patches.
The engine uses a generalization of Loop surfaces. The Shark 3D subdivision technology extends the Loop surfaces in several aspects. First, the vertex normal vector information is taken into account, allowing to mix sharp edges and corners with curved surface parts in any way. Next, texture coordinates are handled in a special way to avoid texture coordinate distortions. As third difference, the engine generates polygon-reduced meshes for patches which are curved only in one dimension. For example, in case of a cylinder, each subdivision iteration does not multiply the number of polygons by four, but only by two. The forth extension is allowing to interpolate between two subdivision stages to avoid "jumping effects".
Curved surfaces
The Shark 3D engine offers two kinds of curved surfaces, which also can be combined.The first technique are mesh patches. This means an optimized storage of meshes which can take optimal advantage of common vertices. This is the fastest technique to draw curved surfaces, since it does not involve any realtime mesh generation. The renderer and its data structures are optimized in such a way that only one call to the 3d driver is needed to draw a patch pass. Only the driver has the work, and the performance only depends on the driver and the hardware. As described above, static precalculated LOD levels can be defined manually or calculated by a tool.
The second technique for curved surfaces are realtime subdivision surfaces. The result usually looks exactly the same way as detailed mesh patches. The main difference is that the detailed patches are calculated in realtime out of few vertices. This costs performance. But in contrast to storing the patch itself, realtime tesselation can save a lot of memory. The memory aspect especially can be important for complex morph animations of curved objects.
Back to Technical Articles